|
por Daniel Pellicer Roig
del Sitio Web
NationalGeographic está formado mayoritariamente por 4 moléculas: adenina (A), citosina (C),
guanina
(G) y timina (T). nuestro pasado, presente y futuro se esconden en nuestros genes. ¿Cuánto sabemos actualmente sobre ellos?
El 14 de abril del año 2003, tras casi 20 años de trabajo a sus espaldas, un grupo formado por científicos de más de 20 países anunció que habían conseguido "escribir" el libro de la vida humana.
Este libro era largo y
complejo, con más de 3000 millones de letras divididas en 23
capítulos, que contenían más del 90% de todas las instrucciones de
las células de los voluntarios que donaron su sangre para el
experimento.
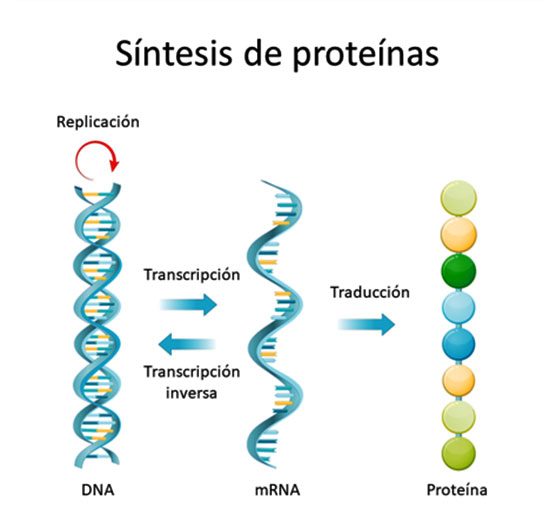
El idioma del ADN está formado mayoritariamente por 4 letras, es decir, 4 moléculas que se repiten una y otra vez en un orden concreto.
Estas moléculas se denominan nucleótidos y son la,
En el idioma de los genes, las letras se agrupan de 3 en 3, lo que da lugar a 27 combinaciones distintas que se denominan codones y que la célula es capaz de entender.
Estas combinaciones de tres letras se van leyendo a toda velocidad y la célula va añadiendo aminoácidos a la cadena hasta que llega a un codón de terminación que le indica que la proteína ha finalizado.
Ahora bien, nuestro cuerpo únicamente necesita 20 aminoácidos, por lo que codones distintos equivalen al mismo aminoácido.
Esta es la razón por la
que los científicos indican que el código genético está degenerado.
DNA a Proteína
En total, se estima que hay algo menos de 20.000 genes que producen proteínas para cumplir con funciones concretas en el organismo. Este número puede parecer grande, pero si lo comparamos con otros seres vivos, no es una cifra muy elevada.
Por ejemplo,
Pero estos son únicamente los genes que tienen la información necesaria para crear una proteína.
El resto de secuencias fueron llamadas erróneamente "ADN basura" porque no se conocía su función y, al no estar aparentemente relacionados con las proteínas, se supuso que no eran tan importantes.
También se encuentran secuencias reguladoras, que reaccionan a diferentes estímulos que recibe la célula y le indican cuándo producir ciertas proteínas vitales para su supervivencia y la del organismo.
Además, encontramos "pseudogenes", que son genes que perdieron su función tras millones de años de acumular mutaciones que se han ido produciendo en nuestra especie.
Estos pseudogenes ayudan
a comprender nuestra historia evolutiva, y estudios recientes
muestran que también pueden tener funciones de regulación de otros
genes activos.
Al principio se pensaba que eran secuencias "de relleno" con una función estructural, pero se ha demostrado que actúan como protección para ciertas zonas, como la parte central y los extremos de los cromosomas.
Además, algunas de estas regiones que presentan más (o menos) repeticiones de lo habitual, pueden estar relacionadas con ciertas enfermedades hereditarias.
Finalmente, también se
encuentran presentes los transposones o "genes saltarines",
unas secuencias que pueden moverse por el genoma y cuyo
descubrimiento le valió a Barbara McClintock el premio Nobel
de Medicina o fisiología en 1983.
Los últimos
descubrimientos del genoma humano
Ahora bien, para seguir indagando en nuestro conocimiento del genoma humano tenemos que avanzar hasta marzo de 2022.
Ese mes, un equipo de la Universidad John Hopkins publicó un artículo en el que mostraba cómo, utilizando técnicas modernas, había conseguido escribir casi todo el ADN que no pudieron en el Proyecto Genoma Humano, el 8% que faltaba...
Esto resulta un reto para las tecnologías de lectura, ya que, para leer al ADN, antes han de romper la molécula en fragmentos pequeños.
Si estos fragmentos
provienen de una zona altamente repetitiva y son prácticamente
idénticos, es muy difícil saber qué trozo va delante, cuál detrás y,
como se leen cientos o miles de moléculas de ADN a la vez, también
resulta casi imposible saber cuántas repeticiones hay en la zona.
Además, entre las secuencias que leyeron se encuentra el cromosoma Y, donde, habitualmente, se sitúan las instrucciones que crean a los machos de nuestra especie.
Esta información es útil para comprender de dónde vienen los rasgos distintivos de cada persona y nos permite encontrar la causa de enfermedades genéticas.
Sin embargo, a pesar de
lo mucho que ha avanzado el conocimiento, todavía existen algunas
lagunas.
Se trata de una lista de genes y otras secuencias que nació con el propósito de desaparecer, ya que son aquellas regiones de las que todavía no conocemos completamente su función...
Estas secuencias son especialmente importantes en la biomedicina, porque pueden interferir en el diseño de tratamientos para enfermedades genéticas.
Estos tratamientos
requieren de años de trabajo y de inversiones monetarias muy
importantes, por lo que todo el conocimiento que ahorre futuros
problemas es bienvenido.
El pangenoma es un objetivo ambicioso para el que se están dando los primeros pasos, y su creación marcará una de las páginas más importantes de nuestra historia.
Una vez lo consigamos podremos responder con certeza a la pregunta que ha atormentado a tantos filósofos:
O al menos podremos hacerlo desde un punto de vista genético...
|